
LLMs are amazing, but they don't know anything about your business. Every conversation, you explain a bit about who you are, what you do, how you operate all over again.
We fine-tune language models on an operational context of your business — a semantic model — so that they don't have to guess who you are or what your business does.
And through semantic discovery and continuous alignment, Rel continues to evolve as your business does.
The magic of Snowflake is that you have already brought all of these types of data together in one place.
The problem is that you’ve brought all of these different kinds of data all in one place. You lose the context and understanding from the source systems. It’s a mess.
To address this, we need to find the meaning in the chaos. We need a semantic model — the set of concepts and relationships that underly your business.

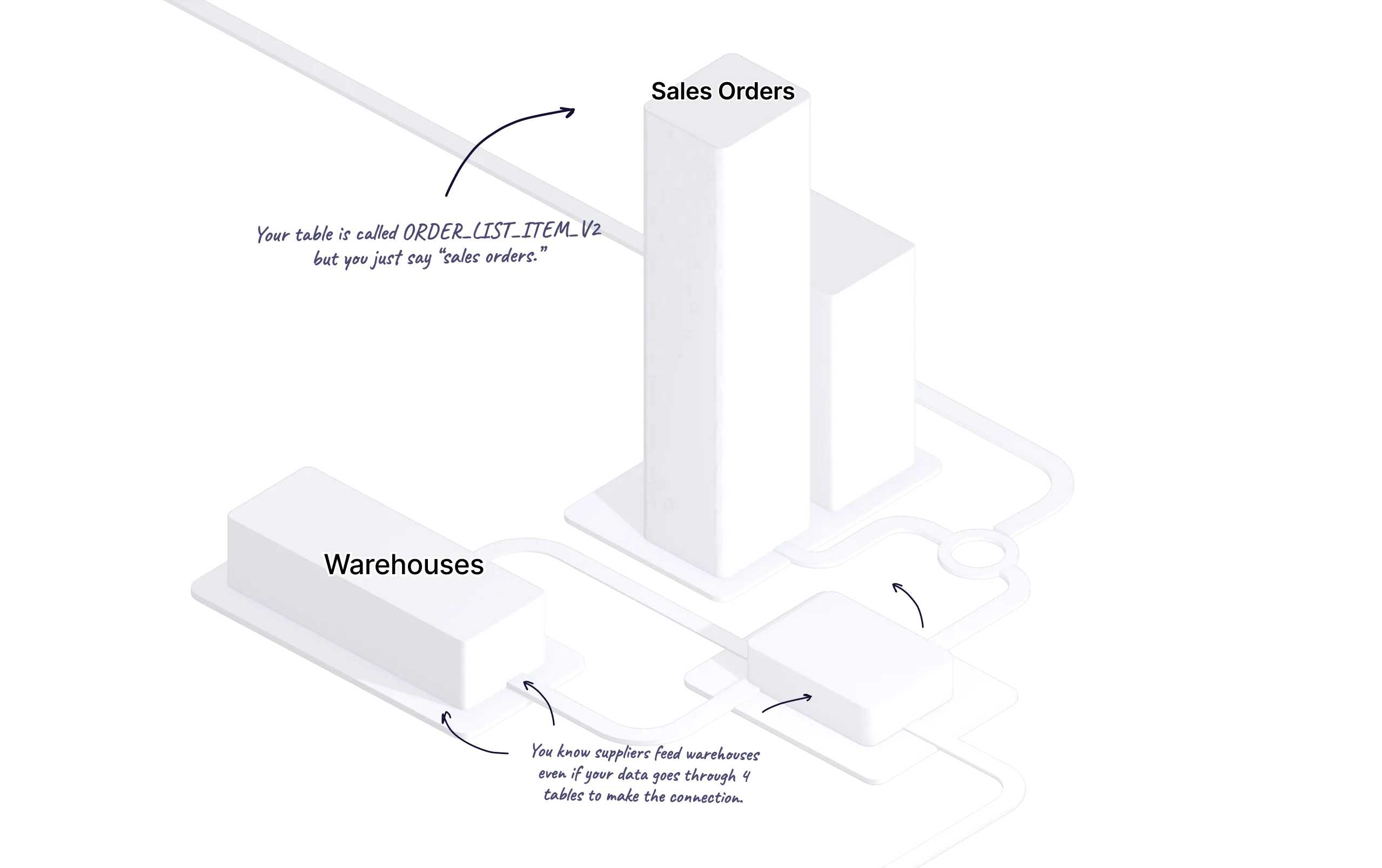
Rel can discover many of the concepts and relationships hidden in all that information, but it also surfaces what it finds so that you can take control and tell us how things really work.

3 suppliers can actually replace Shanghai-Acme if needed:
• Shenzhen-Beta: YES - uses same freight forwarder (can take over existing bookings)
• Mumbai-Delta: NO - lacks certifications for your gift items (3-month approval process)
• Hanoi-Gamma: YES - already pre-qualified as backup (your contracts allow instant switching)
Critical insight: Guangzhou-Alpha has 99% on-time rate but can't be used - they share Shanghai's port congestion risk.
3 SKUs will violate customer contracts:
• GIFT-001: Stockout Feb 15 causes Walmart penalty ($50K/day after 48hr grace period) → Solution: Shanghai must ship by Jan 28 OR air freight
from Hanoi by Feb 10
• GIFT-017: Target's auto-reorder fails Feb 22 (loses preferred vendor status) → Solution: Dallas has 2,000 units reserved for different customer - negotiate swap
• STD-203: Fine IF you execute planned Dallas→Boise transfer by Feb 10
Total risk: $400K in penalties + potential loss of Target preferred status (worth $2.3M/year)
The best generative AI models (LLMs) are trained on publicly available data. The only thing they know about your business is whatever is already public.
Imagine how much better these language models can be at helping you make decisions if we can continuously train them on the private data and institutional knowledge you and your business already have.
Through an innovative fine-tuning method we call “superalignment,” we can do just that. We can see the results in the public benchmarks we compete in today.
Immediate reasoning, even on complex data.
AI for every enterprise,
not just tech giants.
Models adapt in seconds, not overnight.
Your perimeter,
your models.
Your edits become permanent rules. Your definitions become shared truth. Every piece of context you add compounds across your entire organization… and it makes a difference.
• AI that knows you and your business, not just any business.
• Applications that don’t depreciate the moment they launch.
• Reasoning that scales beyond what an LLM can do on its own.
Start building with the Rel API, install the native app inside Snowflake, or get in touch about access to our ready-to-use Rel experience.

Rel is a decision agent aligned to your business, grounded in your semantic model, and powered by the advanced reasoners of the RelationalAI decision intelligence platform.
©2026 RelationalAI. All rights reserved.

%201.jpg)



