
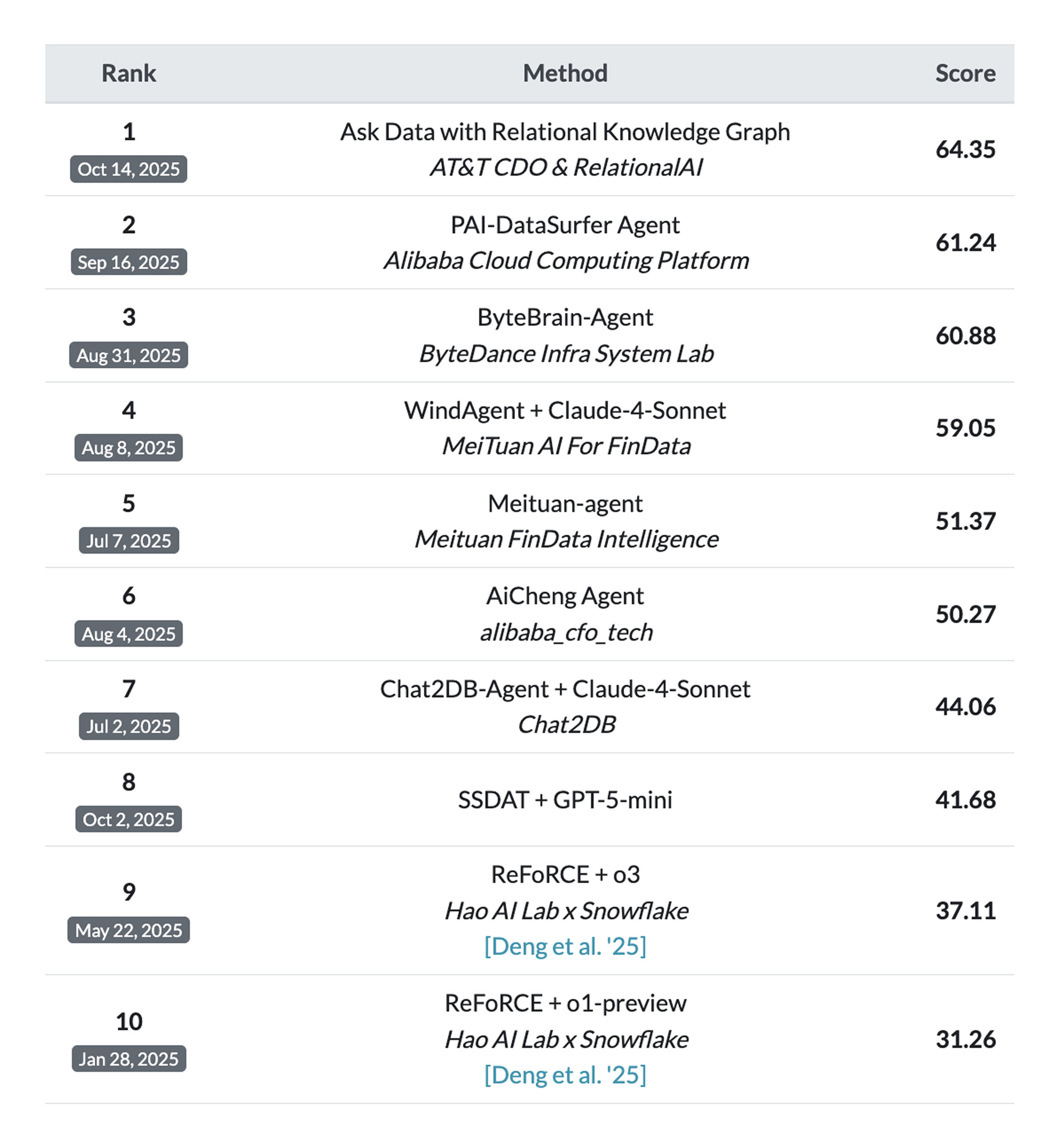
We used a new technology called superalignment to achieve #1 on the Spider 2.0 text-to-SQL benchmark (link) using Qwen3. Superalignment achieves 64.35% on Spider 2.0 Snow compared to the next best submission at the time of 61.24%. We also used superalignment to tune a Llama 3.3 model to push SQL generation accuracy on the BIRD-SQL dev dataset (link) to 93.40%, significantly higher than the best overall dev dataset submission of 76.14%.*
Superalignment builds on and extends LLM fine tuning, RAG, tool usage, and reasoning. It incorporates database technologies including schema linking, schema deduplication and data profiling. It combines these with inference time compute using query consistency. These technologies boost the accuracy of a base Llama 3.3 70B LLM from 56.68% to 93.40% on the BIRD-SQL dev set, and contribute to achieving state-of-the-art performance on the Spider 2.0 benchmark.
Superalignment runs on the open-source ScalarLM integrated LLM inference and training platform, supporting both NVIDIA and AMD GPUs. Schema linking, data profiling, and query consistency use about 40 million tokens of inference time to generate a dataset of high quality tokens that are used for training the final LLM. As these tokens are produced by the ScalarLM inference workers, they are used for back propagation training. The open base model, such as Llama 3.3 or Qwen3, is augmented with Tokenformer adaptors (link), which extend a mixture of memory expert adaptors to train weights on a finer granularity. ScalarLM includes a host of performance optimizations including low precision training, distributed training, and pull-based inference (link) that enable achieving these results efficiently. For instance, we reached our BIRD-SQL result in about 22 hours of GPU compute.

Spider 2.0 is a challenging text-to-SQL benchmark with 547 real-world enterprise database problems that test models on complex workflows requiring multiple SQL queries, often exceeding 100 lines. Unlike previous benchmarks, it uses actual enterprise databases with over 1,000 columns across systems like BigQuery and Snowflake, demanding extensive metadata search, dialect documentation understanding, and codebase navigation. The benchmark is significantly harder than predecessors: a baseline multi-LLM agent (using o1-preview) achieved only 21.3% success on Spider 2.0, compared to 73.0% on BIRD-SQL and 91.2% on the original Spider 1.0. This dramatic performance gap demonstrates that current language models, despite excelling at code generation in simpler benchmarks, still struggle with the complexity of real-world enterprise SQL tasks. Spider 2.0 represents a critical step toward developing autonomous code agents capable of handling production database environments. You can find more details about the Spider 2.0 benchmark in this paper.
In Spider 2.0, we train separate LLMs on the inference time compute results from querying each database using a teacher LLM. This teaches the student LLM about data formats, schema information, semantics, query language quirks, and effective query optimizations. It is typically possible to shrink the student LLM substantially during this distillation process, e.g. we used Qwen 235B to teach Qwen 4B in Spider 2.0. The performance benefits from shorter prompts, smaller models, and optimized inference compound to deliver high accuracy with latency that is comparable to small LLMs instead of many rounds of inference time compute followed by an LLM judge.
In addition to boosting accuracy, superalignment also drastically reduces LLM latency by folding the results from inference time compute back into the LLM’s weights using back propagation. For example, answering one query in the CRYPTO database in the Spider 2.0 benchmark suite required exploring more than 180 candidate queries before selecting the final best query. Using these explored trajectories including reasoning together with the final best query as training data for the aligned LLM simultaneously adds new knowledge discovered by the teacher model using inference time compute, together with generalization information about effective and ineffective reasoning strategies to the student LLM. Generating each candidate query required approximately five minutes of inference time to compute. So the full pipeline ran for over 15 hours to resolve this single question. In contrast, the superaligned LLM produced the correct answer within seconds.
To keep generalization performance of the student LLM high and avoid catastrophic forgetting, we use an optimized LLM-Deflate algorithm to pull general purpose synthetic training from large teacher models as described here.
We find that in addition to instantly writing queries that were previously discovered using inference time compute, superaligned LLMs also generalize better.
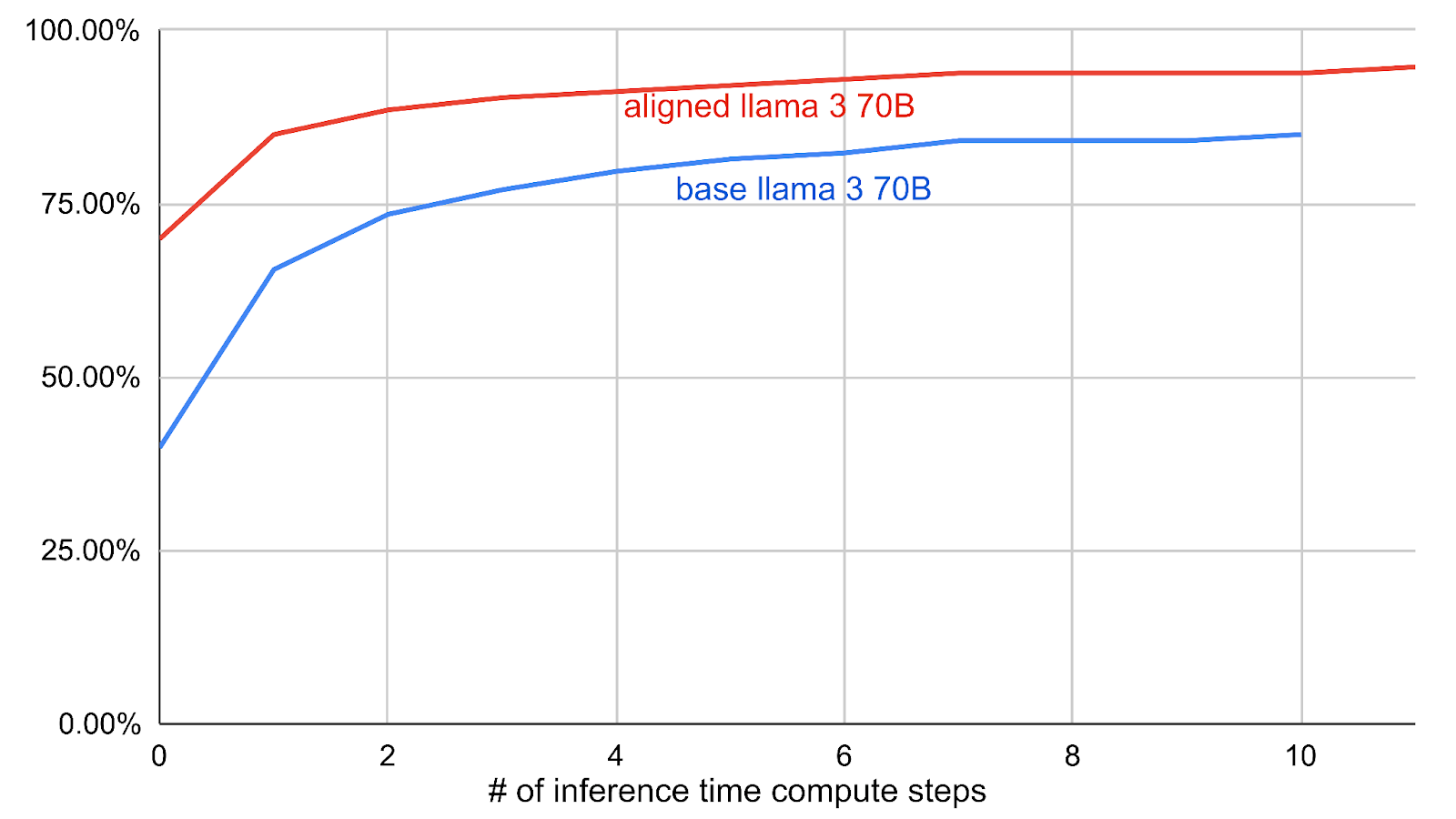
Figure 1 Aligned LLM generalization on BIRD-SQL. This figure shows accuracy on the BIRD-SQL cs_semester database on the vertical axis vs the number of candidate queries generated on the horizontal axis. The aligned model gets more queries correct on the first shot. It also reaches a higher final accuracy after attempting to write 10 candidate queries for each question and selecting the best one, highlighting that the lessons learned by the superaligned student LLM from the training data lead to better generalization.
The zero-shot accuracy gains of superaligned LLMs can be further extended using inference time methods. This process enables relational database users to invest compute in mining additional insights from their data. Unlike prior fine-tuning methods, superalignment requires no explicit training data. The training dataset is the database itself.
The BIRD-SQL (BIg Bench for LaRge-scale Database Grounded Text-to-SQL Evaluation) benchmark is a comprehensive evaluation framework designed to assess text-to-SQL systems on realistic, large-scale database scenarios that mirror real-world complexity. Unlike previous benchmarks that relied on simplified schemas and synthetic questions, BIRD-SQL incorporates actual enterprise databases with intricate relationships, extensive metadata, and domain-specific terminology across sectors like finance, healthcare, and e-commerce. The benchmark challenges models with multi-table joins, nested queries, and business logic requirements while incorporating "evidence" - external knowledge that systems must reason over alongside SQL generation. For engineers and data scientists, BIRD-SQL represents a significant step toward evaluating whether language models can handle production-level database querying tasks, featuring databases with hundreds of tables and requiring sophisticated reasoning about both database structure and domain knowledge to generate correct SQL queries.
Superalignment enables the LLM to deeply understand the data stored in a database, write queries and views to better organize the data, and store this new knowledge in its weights. We have found that this boosts accuracy of the code generated by the LLM. As the LLM learns from the database, its accuracy in solving the BIRD-SQL dev set questions increases, as shown in Figure 2.
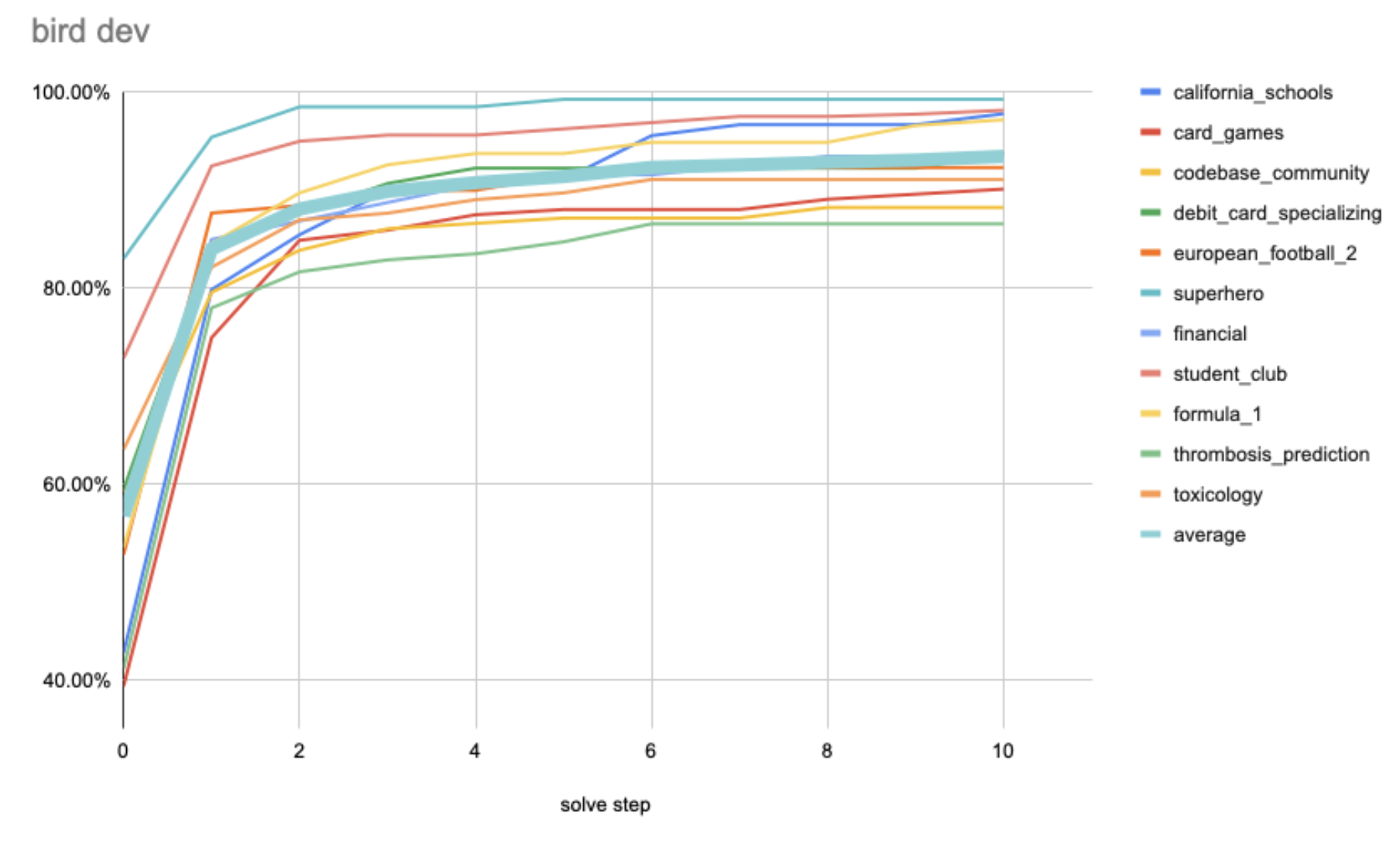
Figure 2 - BIRD-SQL dev set accuracy on the vertical axis vs number of candidate queries judged on the horizontal axis. Investing in more inference time compute using powerful LLMs that are able to learn the database schema and semantics continue to push accuracy up to human levels.
Our method addresses a fundamental challenge: Large Language Models operate based on tokenization, breaking down text into smaller units that the model can understand and process. However, enterprise data stored in relational databases like Snowflake exists in structured table formats with tens of terabytes of information. Direct conversion of database exports to tokens fails because raw CSV or table data lacks the contextual structure and semantic relationships that LLMs need for effective reasoning. The tokenization process would produce disconnected fragments of data without the narrative flow or explanatory context that language models are trained to process.
Our solution employs an agent-based architecture where LLMs query databases dynamically rather than attempting upfront tokenization of entire datasets. The agent receives a question, generates SQL queries to retrieve relevant data from the database, executes those queries, receives results, and then applies reasoning over those results to synthesize an answer. The agent plans tasks, uses tools to execute these tasks, and generates responses by orchestrating across structured data sources—it generates SQL queries from natural language to process structured data and can query the database multiple times as needed. This creates reasoning trajectories where each query-result cycle provides new information that informs subsequent queries. The agent learns through reinforcement learning, receiving rewards for successful reasoning paths and penalties for incorrect ones, gradually improving its ability to formulate effective database queries and interpret results correctly.
We believe that superalignment for databases introduces a key new capability: predictable scaling. Predictable scaling enables a straight shot to superhuman intelligence. It enables LLMs to learn how to build data, rules, relationships, and decision systems automatically with increasing compute. As our scaling results show, SQL coding accuracy increases with more compute invested into superalignment.
We are grateful to our collaborators and partners who made this work possible:
* Footnote from first paragraph: The best overall BIRD-SQL submission is 76.14%, or single-model submission of 72.30% on the dev dataset, and better than human accuracy of 92.96% on the test data set. Most submissions show higher scores on test data than they do on dev data, and unfortunately BIRD-SQL doesn't post human results for the dev dataset.
Start building with the Rel API, install the native app inside Snowflake, or get in touch about access to our ready-to-use Rel experience.

Rel is a decision agent aligned to your business, grounded in your semantic model, and powered by the advanced reasoners of the RelationalAI decision intelligence platform.
©2026 RelationalAI. All rights reserved.
